

Amazon Managed Blockchain is a service by AWS that helps its users create and manage scalable blockchain networks with two leading open-source frameworks: Ethereum and Hyperledger Fabric.
At the moment, only Hyperledger Fabric is available for preview, while Ethereum is planned to be introduced soon.
How to Create Managed Blockchain Networks and Add Members on Amazon MB?
Networks on Amazon Managed Blockchain can include multiple AWS accounts that can share data and execute transactions without the supervision of a central authority.
In order to create a blockchain network on Amazon, you need to use your AWS account. Furthermore, you can use the account to add additional members so as to simulate a network that has multiple accounts.
The preview allows the first member to send invites to other AWS accounts, while other members cannot do that. However, that feature will become available for all members of the network, making it more convenient for new members to join.
However, the network is not owned by any of the AWS accounts. Even if the account that initially created the network were deleted, the network would not cease to exist. In fact, it would continue to live on as long as there are members on it. In other words, the network would stop to exist as soon as the last member was deleted.
The members of the network will be able to vote and decide which new members they want to welcome and which existing ones they want to kick out of the network. Although this feature is not available during the preview, a voting API is on the way and it is planned to be implemented as soon as the service becomes available. The API will also contain configurable rules that will determine the voting process and execute it.
Peer Nodes and Their Role on the Network
Newly added members will be able to configure and launch several blockchain peer nodes that will interact, thus storing a copy of the ledger and processing transaction requests. Each peer node is updated after every transaction to receive the latest global state of the network for the channels in which they participate.
The endorsement process is further defined by the blockchain framework used on the network, as well as the business logic of the participating members. Every member must create at least one peer node and the poorly performing ones will be automatically replaced by Managed Blockchain (MB).
Members can configure applications and tools on peer nodes and interact with other sources on the network by using CLI or SDK — open-source tools that are a part of a client. Your application choice, as well as the client setup, are all determined by the blockchain framework and the development environment that you choose.

How Do Resources on a Managed Blockchain Network Work?
Just like many other decentralized systems, Managed Blockchain requires its members to interact with each other’s peer nodes and resources across the network; that involves making transactions, verifying members, endorsing transactions, and more. Therefore, all of the constituents of one such network need to be named.
All networks, members, and peers nodes are assigned a unique ID, with each network resource exposing a unique, addressable endpoint to other members of the Managed Blockchain network. Those endpoints are created by MB from their unique IDs, and apps or tools based on the blockchain use the endpoints for the purpose of identifying and interacting with resources that are on the Managed Blockchain.
An endpoint for a single resource on the Managed Blockchain network has the following format:
ResourceID.MemberID.NetworkID.managedblockchain.AWSRegion.amazonaws.com:PortNumber
Accessing resources within the network differs from accessing them from the outside.
- Within the network — access and authorization for each resource are governed by processes that are defined within the network.
- Outside the network (applications and tools used by members’ clients) — MB uses AWS PrivateLink in order to make sure that only network members can access resources that they require. In other words, every member is connected via private connection from a client located in their Virtual Private Cloud to the MB network.
Details Related to Amazon Managed Blockchain
Let’s explore some of the details about Amazon MB.
1. Ordering service
Amazon Managed Blockchain ordering service is backed by Amazon’s QLDB (Quantum Ledger Database), which will be discussed in detail later.
2. Fabric CA
Fabric CA is backed by AWS KMS (Key Management Service). The root certificate authority is encrypted using AWS KMS keys.
3. Analytics
In order to alleviate pressure from blockchain resources, it is planned to allow network activity data from the Managed Blockchain network to be sent to the QLDB that you own. There, analysis can be performed using QLDB tools, as well as other specialized analytics tools.
4. Performance
Scientists working at IBM reached a conclusion in a research paper, deducing that Fabric, when configured with some popular deployment configurations, can achieve end-to-end throughput of more than 3500 transactions per second with sub-second latency.
5. Pricing
Amazon Managed Blockchain offers only a preview at the moment, but two editions are expected once it goes live.
Both editions will require that members pay for the following items:
- Network membership fee
- Peer nodes fee
- Peer node storage fee
- Fee for the amount of data that members write to the network
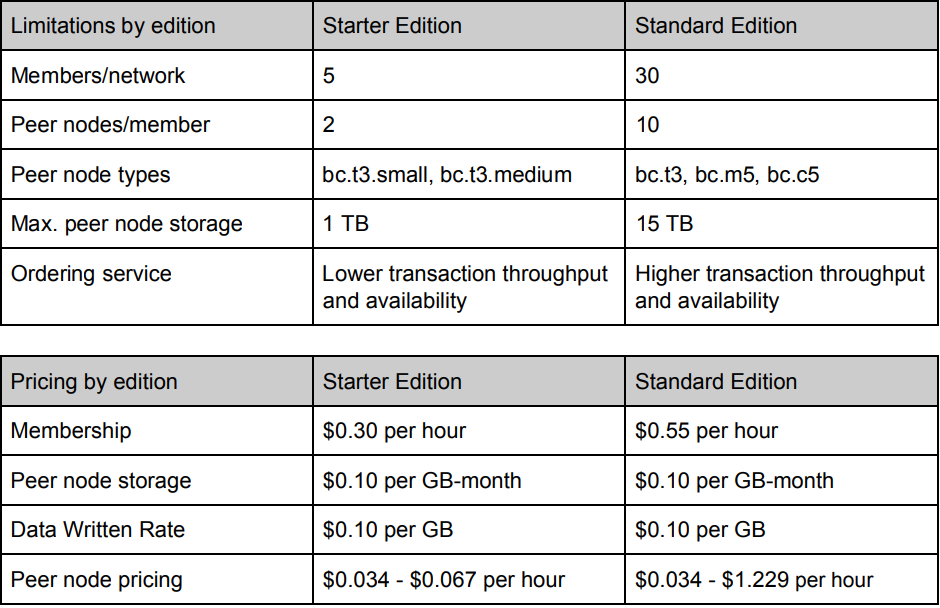
Check out Amazon Managed Blockchain pricing and Amazon Managed Blockchain Instance Types for more details.
Amazon Quantum Ledger Database (QLDB)
Quantum Ledger Database offered by Amazon does not differ from other cryptographically verifiable transaction logs, as it makes the logs not only transparent but also immutable.
This fully managed ledger database is owned by a central trusted authority and is able to track all application data changes as well as maintain a history of changes over time, both of which are complete and verifiable.
How Does Amazon QLDB Differ from Other Ledger Implementations?
Ledger applications can be implemented using relational databases, audit tables, or audit trails. However, these are not flawless since they can be quite resource-intensive, as well as difficult to scale. Furthermore, to record events in the precise order of occurrence, the applications require additional serialization that slows them down.
One way to solve these problems is to implement additional code that is, naturally, error-prone. Finally, since the applications are not inherently immutable, changes can be made easily, but tracking and identifying unintended changes is really difficult.
Blockchain frameworks such as Ethereum and Hyperledger Fabric can also be used for ledger applications, but these too come at a cost. In case the applications do not require inherent decentralization provided by the frameworks, such as the two mentioned above, setup complexity can significantly increase as it requires setting up a whole blockchain network.
Consequently, transactions would slow down due to the validation process that nodes must perform for every transaction before they are submitted to the ledger. Furthermore, one such network would require maintenance, which would be an additional burden.
Amazon QLDB eliminates all this overhead work by providing immutability and the ability to cryptographically verify whether there were unintended modifications of data. Apart from SQL-like API, document data model, and full support for transactions, QLDB by Amazon is also serverless and is able to scale so as to support your application demands automatically. In other words, there is no need to neither configure nor manage any servers.
How Does QLDB Work?
The ledger consists of an immutable, append-only journal, and contains tables that display both its current state and its history, making it easy for us to access the state of the ledger at any point in time. If we were to use the financial ledger analogy, QLDB journal would work just like a list of credits and debts, as well as a table displaying the current balance.
Let’s use a ledger that tracks car ownership over time as an example:
- You buy a car.
- Data is inserted in the journal as a transaction.
- Data is recorded in the current.cars and history.cars tables.
- Peter buys your car.
- A new transaction is created.
- current.cars table is changed but history.cars adds another row that tracks new changes of your car and labels it as version 2.
- Igor from Russia buys your car, which means that it needs to be deleted from the database.
- current.cars now has no rows while history.cars adds another row that is labeled as version 3 and contains the deleted values.
How Is QLDB Verifiable?
The API of QLDB contains no instructions on how to modify history tables; that would be contrary to their primary purpose — displaying the history of changes for a specific item in the journal. Furthermore, API lacks instructions for modifying existing journal entries since all changes to the journal must be stored as newly appended transactions.
In order to ensure immutability, the journal is cryptographically hashed. Whenever a transaction is committed to the journal, it is passed through a SHA-256 hash function that produces a digest of that transaction — H(T1).
That process is applied to all transactions that are written into the journal. However, every additional transaction after the initial one passes the digest of the previous transaction into the hash function. In other words, the hash of the second transaction H(T2) is actually H(H(T1) + T2). Therefore, we can make a general function: H(Tn) = H(H(Tn-1) + Tn).
Small changes in the input can cause huge changes in the output in cryptographic hash functions. In fact, changing a single character in a transaction string results in a completely different hash output for that transaction. Therefore, in order to make a change appear valid, one would need to change all previous transactions so that their hash digests create a chain that validates the new hash digest of the changed transaction.
Fortunately, finding what data was passed into a hash function to produce the known input is infeasible. Even if one succeeded in such an endeavor, saving a single digest from previous transactions would be enough to confirm that the newly generated digests do not add up.
Hyperledger Fabric
Just like Ethereum, Hyperledger Fabric is a blockchain framework implementation. It is a project by Hyperledger that is hosted by The Linux Foundation and was conceived by Digital Asset and IBM during the first hackathon organized by these two companies.

The basic idea behind it is to create a foundation for modular architecture applications and solutions. Furthermore, it enables components such as membership services and consensus to be plug and play.
Hyperledger Fabric includes a couple of concepts that are integral parts of this technology.
Chaincode
When a piece of code is written in one of the supported languages such as Java, Go, or Node.js, it is installed to the Hyperledger Fabric network’s peer nodes and it can further interact with the shared ledger of that network.
Permissioned Platform
Participants know each other on the network, unlike in other blockchain systems that are permissionless, and unknown parties are allowed to take part in the network too. Hyperledger Fabric network uses a trusted MSP (membership service provider), which allows members to enroll.
Pluggable Consensus
The ordering of transactions is delegated to a modular component for consensus that is logically decoupled from the peers that execute transactions and maintain the ledger — the ordering service, to be specific.
Since the consensus is modular, its implementation can be tailored to the trust assumption of a particular deployment or solution. A Fabric network can have multiple ordering services supporting different applications or application requirements.
In short, the customization levels of this framework can fit particular use cases and trust models.
No Native Cryptocurrency Required
In other words, the platform can be deployed with roughly the same operational cost as any other distributed system.
Modularity
To a large extent, Fabric is comprised of the following modular components:
- A pluggable ordering service that establishes consensus on the order of transactions and then broadcasts blocks to peers.
- A pluggable membership service provider that is responsible for associating entities on the network with cryptographic identities.
- An optional peer-to-peer gossip service that disseminates blocks output by ordering service to other peers.
- Smart contracts (“chaincode”) that run within a container environment (e.g. Docker) for isolation. They can be written in standard programming languages but do not have direct access to the ledger state.
- The ledger that can be configured to support a variety of DBMSs.
- A pluggable endorsement and validation policy enforcement that can be independently configured per each application.
Smart Contract Architectures
Smart contracts are called chaincode in Hyperledger Fabric. First of all, let’s take a look at the two existing types of architectures of smart contracts:
- Order-Execute Architecture
The following happens as a part of this architecture:
- Consensus protocol validates and orders transactions; then, it propagates them to all peer nodes.
- Each peer node then executes the transactions sequentially.
This process creates a couple of problems that are difficult to solve.
First of all, in order to reach the consensus, smart contracts are required to be deterministic. To solve the non-determinism issue and eliminate non-deterministic operations, many platforms require using non-standard or domain-specific languages (such as Solidity) for writing smart contracts.
Secondly, both performance and scale are limited since all transactions are executed sequentially by all nodes.
Finally, the fact that the smart contract code executes on every node in the system demands that complex measures be taken to protect the entire system from potentially malicious contracts and ensure its resiliency.

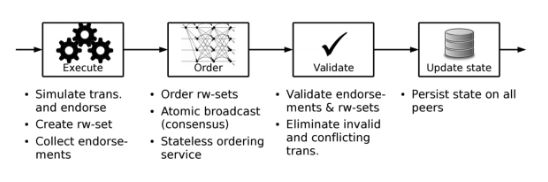
2. Execute-order-validate architecture (used by Fabric)
This type of architecture overcomes challenges related to resilience, flexibility, scalability, performance, and confidentiality by separating the transaction flow into three steps:
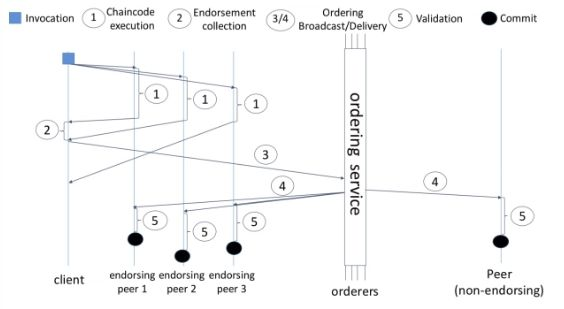
- Execute a transaction and check its correctness, thereby endorsing it.
- Order transactions via (pluggable) consensus protocol.
- Validate transactions against an application-specific endorsement policy before committing them to the ledger.
The application-specific endorsement policy specifies the peer nodes (and their number) that are required to vouch for the correct execution of a smart contract at hand. In other words, every transaction needs to be executed (endorsed) by only a subset of peer nodes, which paves the way for parallel execution.
Furthermore, any instances of non-determinism are eliminated right away, as inconsistent results are filtered out before ordering. The elimination of non-determinism enables using standard programming languages with Fabric (Go, Node.js, and Java).
Privacy and Confidentiality
Public and permissionless blockchain networks that leverage PoW for their consensus model execute transactions on every node. In other words, every transaction, along with the code implemented in it, is visible to every node on the network.
Thanks to the channel architecture deployed by Fabric, networks are able to establish “channels” between the subset of participants who are, thus, granted visibility to a particular set of transactions. Therefore, only the nodes that are a part of that channel can access the smart contract (chaincode) and the data transacted, preserving the privacy and confidentiality of both.
Identity and MSP
Each actor in a blockchain network (both inside and outside) who is able to consume services has a digital identity encapsulated in an X.509 digital certificate. These identities determine the exact permissions over resources and access to information that actors have in the blockchain network.
Digital identities are subject to additional attributes used by Fabric to determine permissions. Fabric uses the term principal to denote an identity with associated attributes. Principals also include properties such as actor’s organizations, organization units, roles, and even the actor’s specific identity. Basically, principals are the properties that determine permissions of the actors.
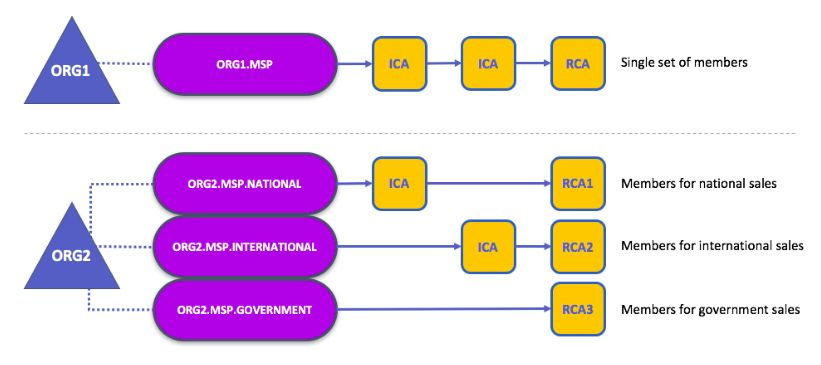
For an identity to be verifiable, it must come from a trusted authority. A membership service provider (MSP) is used to achieve that in Fabric.
MSP is a component that defines the rules that govern valid identities for organizations. It identifies which Root CAs and Intermediate CAs are trusted to define members of an organization.
An organization is a group of members managed either under a single MSP or multiple MSPs.
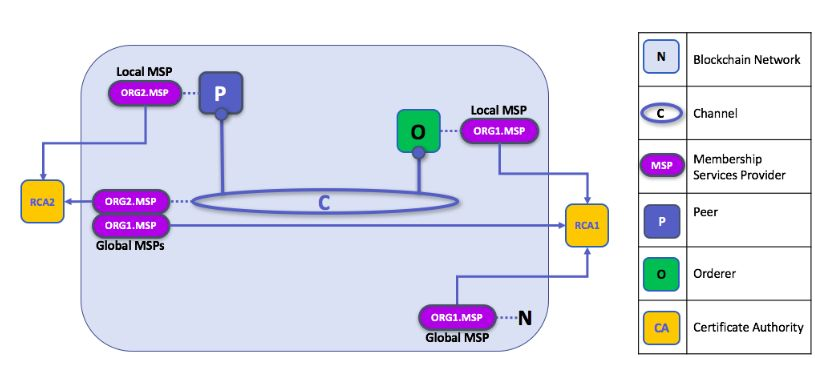
Local and Channel MSPs
Two forms of MSP appear in Fabric:
1. Channel MSP
Channel MSP determines admin and participation rights at the channel level. Every organization participating in a channel must have an MSP defined for it. That is to say, peers and orderers in a channel all share the same view of channel MSPs, and if an organization wishes to join the channel, an MSP incorporating the chain of trust for the organization’s members would need to be included in the channel configuration. Otherwise, transactions originating from identities of this organization would be rejected.
2. Local MSP
Local MSP defines permissions for specific nodes (ex. Who the admins are), and for specific users. MSP allows the user-side to authenticate itself in its transactions as a member of a channel, or as the owner of a specific role in the system. Every node and user must have a local MSP defined, as that determines who has admin or participation rights at that level (peer admins are not always channel admins and vice versa).
Local MSPs are only defined on the file system of the node or the user to which they apply. That means that there is only one local MSP per node or user.
Channel MSPs are available on all nodes in the channel. Once in the channel configuration, they are logically defined. However, physically, a channel MSP is instantiated on the file system of every node in the channel and kept in sync via consensus.
MSP Levels
Channel and local MSPs exist because organizations need to administer their local resources (ex. peer/orderer nodes), as well as their channel resources (ex. ledgers, smart contracts) that operate at the channel or network level.
If we think about these MSPs as being at different levels, then MSPs at higher levels relate to
network administration concerns, while MSPs at lower levels handle identity for the
administration of private resources.
- Network MSP — The configuration of a network defines who the members on the network are by defining the MSPs of the participant organizations, as well as which of these members are authorized to perform administrative tasks (e.g. creating a channel).
- Channel MSP — Channel policies interpreted in the context of that channel’s MSPs define who has the ability to participate in a certain action on the channel (e.g. adding organizations, instantiating chaincodes).
- Peer MSP — This local MSP is defined on the file system of each peer with a single MSP instance for each peer. It performs the same function as channel MSPs but it only applies to the peers where it is defined. Installing chaincode on the peer is authorized using the peer’s local MSP.
- Orderer MSP — Orderer local MSP is also defined on the file system of the node and only applies to that node. Orderers are owned by a single organization and have a single MSP to list the actors or nodes they trust.
Further Reading
If you want to learn more about Managed Blockchain, gain a deeper insight, and try it out yourself, check out this blogpost by Amazon.
The article shows you in four steps how to create a personal Hyperledger Fabric network with Managed Blockchain and deploy an application for tracking donations to nonprofit organizations via that network.
Follow us and subscribe for more deep dives into the technology like this one, and feel free to join the conversation on Twitter and LinkedIn.
Our team of engineers works day in and day out on developing blockchain products, and we strive to learn more from others. Get in touch with us if you would like to share your experience so that together we can help to grow blockchain community of builders even further.
Amazon Managed Blockchain was originally published in MVP Workshop on Medium, where people are continuing the conversation by highlighting and responding to this story.


