
UPDATED ON 05.11.2020
During the last decade, it seems that the majority of the data we use has moved onto cloud storage. Most of the apps we use daily store personal data in centers owned by Microsoft, Google, or Amazon.
In an attempt to pioneer a new, better internet – Web 3.0, developers are starting to use decentralized networks as a way to improve data availability, resiliency, and ownership rights. Innovative technologies such as the Interplanetary File System (IPFS) enable us to improve Web 2.0 and its protocols, making the internet safer by using a global network of peers to distribute data.
IPFS was created in 2015 to create a system that could change how we keep, transmit, and use information. Currently, millions of people use IPFS.
The underlying technology of IPFS

<tl;dr> In this article we’ll discuss the Interplanetary File System (IPFS) alongside all of its functionalities and components. As we dive deeper into the subject, we are going to shift focus to DHT (distributed hash table) and Git’s MerkleDAG implementations in IPFS. Feel free to jump on the part you are most interested in.
The underlying technology of IPFS
It is crucial to understand the importance of these concepts due to the fact that almost all technological solutions in the P2P systems nowadays are relying on these technologies.
Firstly, let’s take a look at some of the “problems” with Web 2.0 today:
- Location-based addressing
It might not seem like a problem, after all, that’s how the web works. Having to access your data on a server from the other part of the world might bring some time complexity to the table.
- Centralization & single point of failure
This is a well-known problem where if a centralized server goes down, there is no way to access any of the data you might need.
- Censorship
The whole point of the internet is to share data, but while we have potent entities restricting our access to information, we will not have the data liberation that we seek.
- Impermanence
Lots of links are broken, out of 1.8 billion websites in the World, only 200 million is live.
What is IPFS?
IPFS stands for an Interplanetary file system and it aims to change the way we distribute and work with data today. The InterPlanetary File System is a peer-to-peer distributed file system that seeks to connect all computing devices with the same system of files. It is combining well-tested internet technologies such as DHT (distributed hash tables), Git’s MerkleDAG, and BitTorrent’s bit swap protocol. It uses content addressing block storage and data structure in the form of MerkleDAG upon which one can build a versioned file system, blockchains, etc..
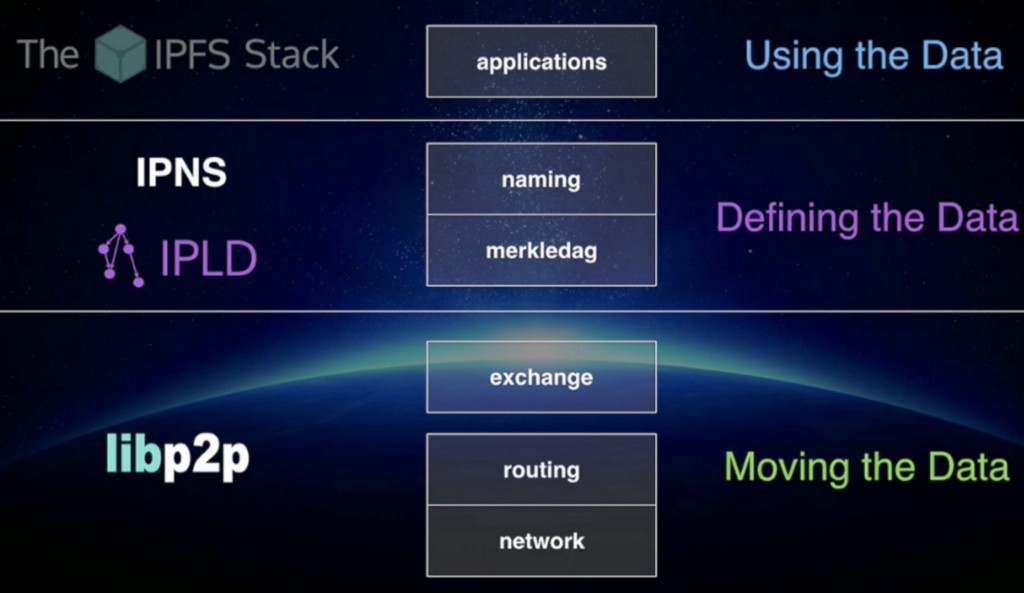
IPFS has five layers:
- naming — a self-certifying PKI namespace (IPNS)
- MerkleDAG — data structure format (thin waist)
- exchange — block transport and replication
- routing — locating peers and objects
- network — establishing connections between peers
Network
The network provides point-to-point transports (reliable and unreliable) between any two IPFS nodes in the network.
- NAT traversal — hole punching, port mapping, and relay
- supports multiple modes of transport — TCP, SCTP, UDP, …
- supports encryption, signing, or clear communications
- multi-multiplexes -multiplexes connections, streams, protocols, peers
Routing — DHT
Before we jump into routing in IPFS let’s take a look at the different ways of finding an object. There are two basic ways, searching and addressing. Searching is how google works; it finds an object by searching with keywords that match object description, i.e., comparing the actual object to know if they are the same. This makes it hard to be efficient.
Addressing, on the other hand, finds objects by addressing them with their unique name. The best example is the URL on the Web. The pros of this approach are that object location can be more efficient and every object is uniquely identifiable.
Searching in P2P networks is not efficient, finding a solution in ether centralized, distributed or even hybrid method does not provide the system with desirable speed efficiency. Creating a more efficient search and object location was the original motivation for researching distributed hash tables. One major goal of P2P systems is object lookup: Given a data item X stored in some set of nodes in the system, find it.
What is DHT
DHT performs the functions of a hash table. You can store a key and value pair, and you can look up a value if you have the key. Let’s take a look at hash tables to get a better understanding of what DHTs are:
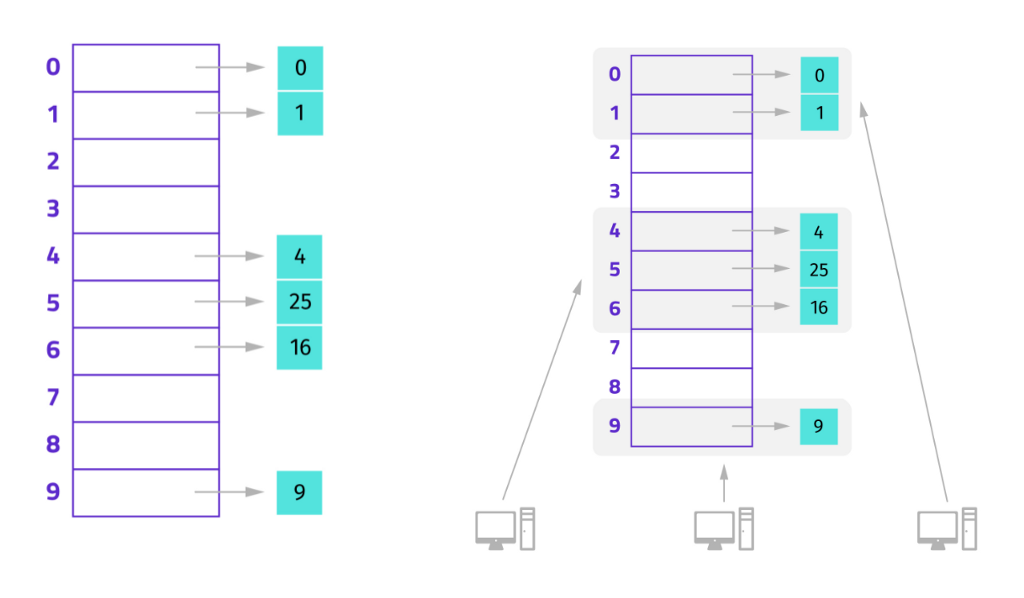
The task of maintaining the mapping from keys to values is distributed among the nodes, in such a way that a change in the set of participants causes a minimal amount of disruption.
In a DHT, each node is responsible for one or more hash buckets. As nodes join and leave, the responsibilities change. Nodes communicate among themselves to find the responsible node, and scalable communications are what make DHTs efficient. DHTs also supports all the normal hash table operations.
Let’s first take a look at how basic DHT works after which we will take a look at IPFS implementation of Kademlia DHT.
Upon the creation of the DHT, hash buckets are distributed among nodes. The process is starting by dividing buckets over nodes that are already in the network. Nodes are forming an overlay network connected by virtual or logical links. A routing scheme is established. DHT behavior and usage differ for different implementations, but when we talk about the basic concept the procedure is like the following:
- A node knows the “object” name and wants to find it
- Node routes a message in an overlay to the responsible node
- Responsible node replies with “object”
The characteristics of any implementation of DHT are autonomy and decentralization which means nodes collectively form the system without any central coordination. The system is fault-tolerant, i.e., should be reliable even with nodes continuously joining, leaving, and failing. DHTs are scalable, and it should function efficiently even with thousands or millions of nodes.
Quick tip: check how Cord DHT works.
How does Kademlia DHT look like
Unlike other DHT routing systems, Kademlia uses tree-based routing. Kademlia binary tree treats nodes as leaves of a binary tree, starting from the root, for any given node, dividing the binary tree into a series of successively lower subtrees that don’t contain the node. Every node keeps touch with at least one node from each of its subtrees. Corresponding to each subtree, there is a k-bucket.
In this forest, every node needs to keep a list of (IP-address, Port, Node-id) triples, and (key, value) tuples for further exchanging information with others.
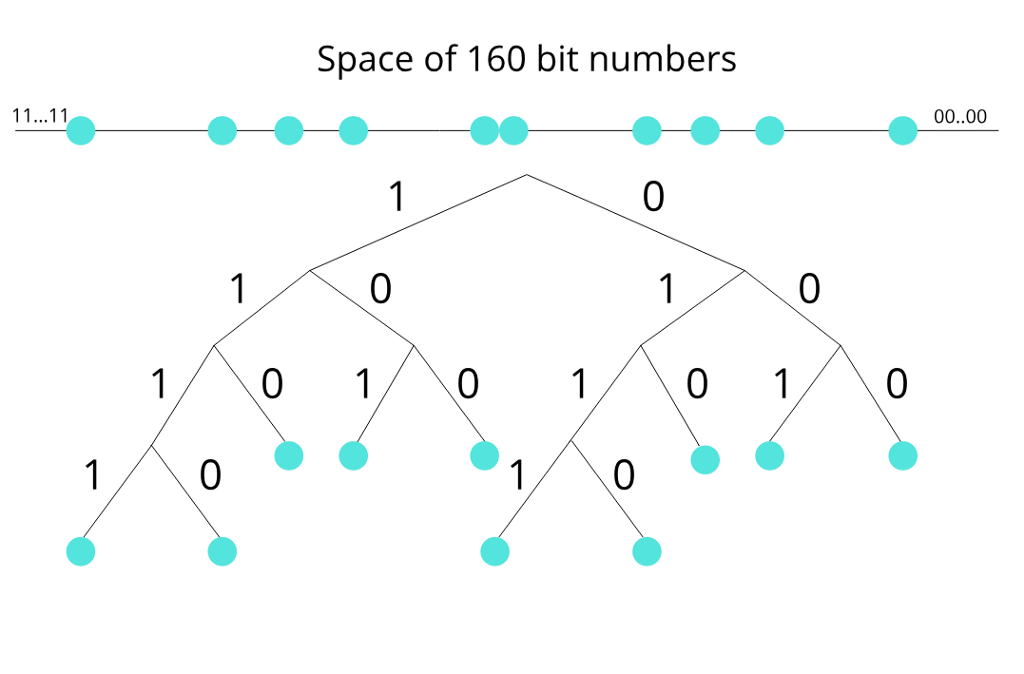
Nodes, files, and keywords, deploy SHA1 hash into a 160-bit space. By each node, information about files and keywords are kept just for the closest nodes.
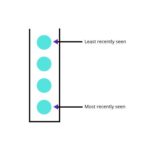
For each i (0 ≤ i < 160) every node keeps a list of nodes of the distance between 2^i and 2^(i+1) from itself. Each list is a k-bucket. The list is sorted by the time last seen. The value of k is chosen so that any given set of k nodes is unlikely to fail within an hour. The list is updated whenever a node receives a message.
The nodes in the k-buckets are the stepping stones of routing. By relying on the oldest nodes, that they will remain online. DoS attack is prevented since the new nodes find it challenging to get into the k-bucket.
Kademlia RPC — remote procedure call
- PING: to test whether a node is online
- STORE: instruct a node to store a key
- FIND_NODE: takes an ID as an argument, a recipient returns (IP address, UDP port, node id) of the k nodes that it knows from the set of nodes closest to ID (node lookup)
- FIND_VALUE: behaves like FIND_NODE, unless the recipient received a STORE for that key, it just returns the stored value
To store a (key, value) pair, a participant locates the closest k nodes to the key and sends them STORE RPCs. For Kademlia’s file-sharing application, the original publisher of a (key, value) pair is required to republish it every 24 hours. Otherwise, (key, value) pairs expire 24 hours after publication.
Fault tolerance and concurrent change are handled well via the use of k-buckets. Proximity routing chooses nodes that have low latency and handles DoS attacks by using nodes that are up for a long time.
Block Exchange
Bitswap is the data exchanging model used in IPFS, it manages to request and send blocks to and from other peers in the network. Bitswap serves two main purposes, first is to get blocks that are requested by the network (it have routes because of DHT). The second is to send those blocks to nodes that want them.
Bitswap is a message based protocol, as opposed to response-reply. All messages contain want lists or blocks. Upon receiving a want list, a node should consider sending out wanted blocks if they have them. Upon receiving blocks, the node should send out a notification called a ‘Cancel’ signifying that they no longer want the block. At a protocol level, bitswap is very simple.
MerkleDAG
In a MerkleDAG, Merkle stands for Merkle Tree and DAG for a direct acyclic graph. Which means this data is similar to the Merkle tree but not so strict, so DAG does not need to be balanced, and its non-leaf nodes are allowed to contain data.
“Merkle trees make it possible for the web to be built on a small contribution of many rather than concentrated resources of a few.”
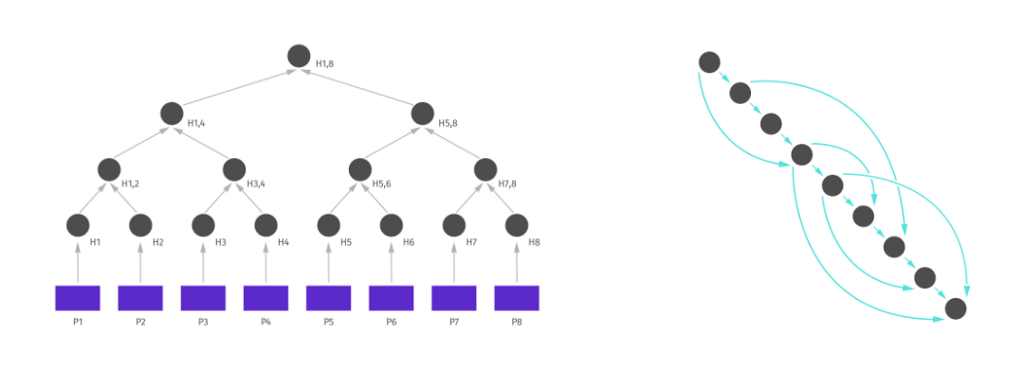
When we combine them we get something like this:
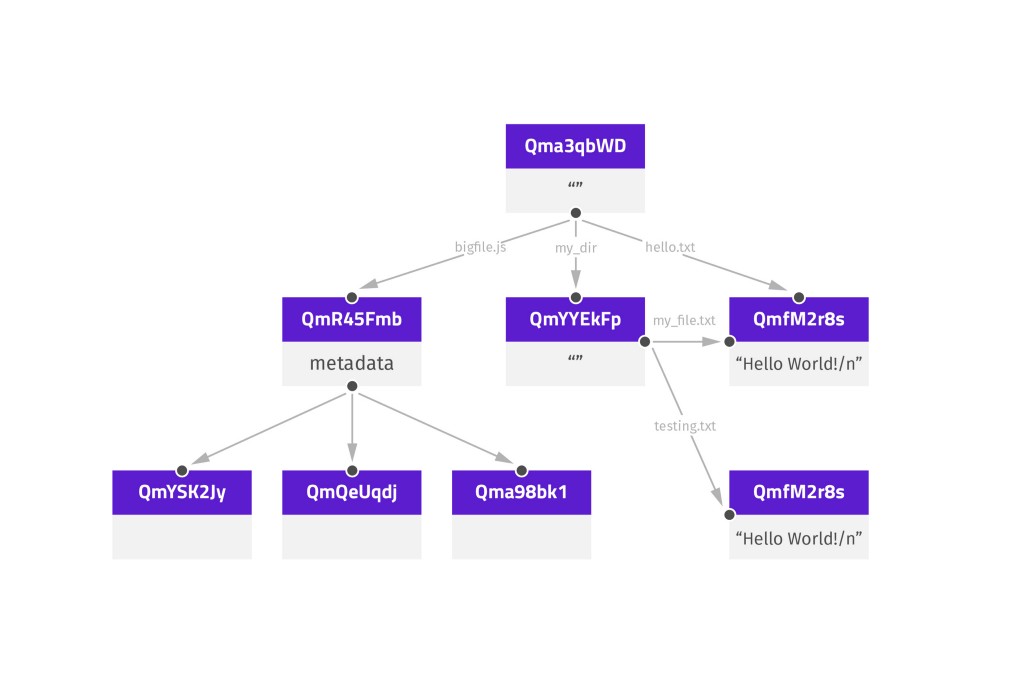
IPFS object is a MerkleDAG data structure that has two fields, data and an array of links when we do ipfs object get QmfM2r8s.. (or the middle right object in the picture< 256Kb) we get something like this:
"Links":[{"Name":"",
"Hash":"QmYSK2Jy...",
"Size":2621 }]
"Data":"\u0008\Hello World!..."} - each object data is up to 256Kb
But when we have data that is bigger than 256Kb (middle left object) we will have an array of link structures with different hashes pointing to parts of data which was previously fragmented.
"Links":[{"Name":"" ,
"Hash":"QmYSK2Jy...",
"Size":2621 }]
"Links":[{"Name":"" ,
"Hash":"QmQeUqdj...",
"Size":564261 }]
"Data":"\u0008\u..."}
Every hash is unique because every one of them is produced with an SHA-256 algorithm based on the data content. This content addressing gives IPFS the ability to deduplicate files automatically. That means if we have two files that contain the same data the hash produced by both will be the same and will point to one object place.
Merkle DAG also gives us the ability to have a versioned file system. There are two main reasons why versioning is essential, first is being able to access history or how the data has been changed over time. The second is being able to link to any one of those versions, forever.
Let’s take a look at how the Git versioning system works. Create two files: test.txt and hello_world.txt

It will add hashes to each file. When we add files to git (git add), it will create a tree object:
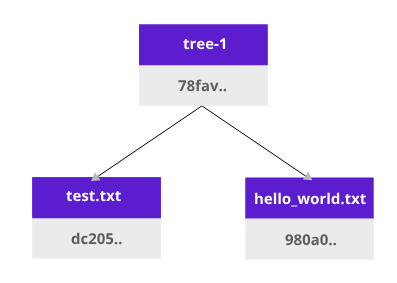
This tree1 object (Merkle tree) is dependent on the content of test.txt and hello_world.txt. That means if we change either of our .txt files the hash of the tree1 object will change. After a git commit, more data about the owner is added, therefore it is added to a new hash.
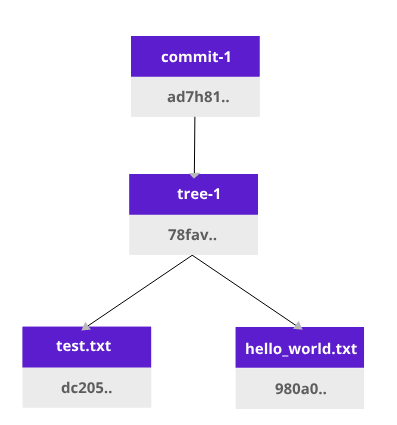
Now we have a Merkle tree with our two files. This is what happens when we edit a test.txt file:
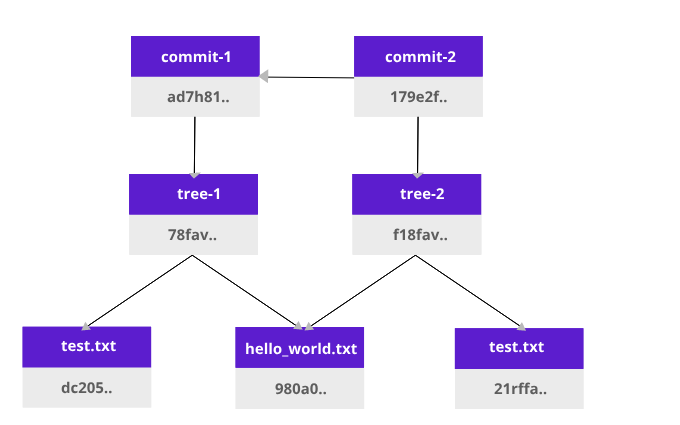
The new tree (tree2) is created, and its commit (commit2) will depend on the first commit with the original files (commit1). This allows us to have versioning.
So in general, combining these properties together we have MerkleDAG data structure which acts like a “thin-waist” for secure, distributed applications, which by agreeing to follow the common format can then run across any replication, routing, and transport protocols.
Naming
Because changing an object would change its hash (content addressing) and thus its address, IPFS needs some way to provide a permanent address and even better human-readable name. This is addressed with IPNS (interplanetary naming system) which handles the creation of:
- mutable pointers to objects
- human-readable names
IPNS is based on SFS. It is a PKI namespace a name is simply the hash of a public key. Records are signed by the private key and distributed anywhere.
Blockchain
This is one of the most interesting use cases for IPFS. A blockchain has a natural DAG structure, considering that previous blocks are always linked by their hash from the later ones. Ethereum blockchain also has an associated state database that has a Merkle-Patricia tree structure that can be emulated using IPFS objects.
A key point here is the difference between storing data on the blockchain and storing hashes of data on the blockchain. On the Ethereum blockchain, users pay a large fee for storing data in the associated state database, in order to minimize the bloat of the state database (so-called “blockchain bloat”). This is a standard design pattern for larger pieces of data that do not store the data itself, but an IPFS hash of the data in the state database.
Usually, blockchains make a distinction between what is in the global ledger replicated by every miner (aka, data stored in the chain itself) and the data that might be referenced within the chain but isn’t replicated between all nodes and should be checked up separately (because it is too large). If the blockchain with its associated state database is already embodied in IPFS, then the distinction between storing a hash on the blockchain and storing the data on the blockchain becomes somewhat blurred, since everything is stored in IPFS anyway.
Conclusion
As we all know, HTTP is one of the most successful file distributed systems and is worldwide used. Shifting towards peer-to-peer data distribution systems is not an easy task. While today we have such amazing solution concepts it’s just up to us which direction we are going to take them. Since the world is headed towards peer-to-peer systems, DHT and MerkleDAG is a great place to start. IPFS alongside FileCoin is taking a huge leap towards decentralized storage of personal data in which all of us should take part.
A Closer Look at the InterPlanetary File System (IPFS) was originally published in MVP Workshop on Medium, where people are continuing the conversation by highlighting and responding to this story.


